1. Introduction
There are many reasons why two houses might have different prices. To start with, one house might just be larger or have a better layout than the other. Let’s call these sorts of house-to-house differences “fine-grained”. But, prices can also vary for reasons that have nothing to do with the houses themselves. Even if two houses are physically identical, one house might sit in a more attractive neighborhood or belong to a better school district. Let’s call such differences over larger scales “coarse-grained”.
Different scales dominate in different places. In some counties, most of the price variation comes from fine-grained, house-to-house differences. Think about Los Angeles, CA where there is a lot of heterogeneity in the age and quality of the housing stock, even for houses that are right next door to one another. But, there are also coarse-grained counties where most of the house-price variation occurs over much larger scales. Think about Orange County, CA where the typical house is part of a subdivision. While there are lots of differences between subdivisions in Orange County, all the houses within each subdivision are typically built in a similar style by a single company at the exact same time.

This post shows how to estimate the characteristic scale of house-price variation in a county. That is, it shows how to tell if a county is fine-grained like Los Angeles, coarse-grained like Orange County, or somewhere in between. To do this, I introduce a new scale-specific variance estimator based on the Allan variance. This estimator decomposes the cross-sectional house-price variation in a given county into scale-specific components such as the amount of variation that arises from comparing randomly selected houses or the amount of variation that arises from comparing randomly selected neighborhoods.
Why not just compare the variance of the individual house prices to the variance of the neighborhood-level averages? The answer is simple: those calculations aren’t independent. Fine-grained counties with lots of house-to-house variation will mechanically have more variance in their average neighborhood-level prices. Just imagine the extreme case where all of the variation comes from house-to-house differences and each house’s price is independently drawn from the same normal distribution,  . In a world where the
. In a world where the  th neighborhood has
th neighborhood has  houses, the variance of the neighborhood-level average price,
houses, the variance of the neighborhood-level average price,  , would be increasing in the amount of house-to-house variation,
, would be increasing in the amount of house-to-house variation,  . I use this new scale-specific estimator because I don’t want to confuse these sorts of emergent neighborhood-level fluctuations with the honest-to-goodness neighborhood-level differences.
. I use this new scale-specific estimator because I don’t want to confuse these sorts of emergent neighborhood-level fluctuations with the honest-to-goodness neighborhood-level differences.
2. Data-Generating Process
Consider a county with  houses and
houses and  neighborhoods where there are
neighborhoods where there are  houses in each neighborhood so that
houses in each neighborhood so that  . Suppose that house prices are the sum of a neighborhood-level value and a house-level value,
. Suppose that house prices are the sum of a neighborhood-level value and a house-level value,
(1) 
with  and
and  . Think about neighborhood-level values as the quality of the local school district or the attractiveness of the nearby restaurant scene. This value is coarse-grained. You can have a mansion or a hovel in a nice school district. The house-level value, by contrast, relates to the characteristics of each particular house. This value is fine-grained.
. Think about neighborhood-level values as the quality of the local school district or the attractiveness of the nearby restaurant scene. This value is coarse-grained. You can have a mansion or a hovel in a nice school district. The house-level value, by contrast, relates to the characteristics of each particular house. This value is fine-grained.
Given this data-generating process, we know that a fraction
(2) 
of the variation in house prices comes from neighborhood-level differences. This is the object of interest in the current post. If  is close to
is close to  , then the county is dominated by coarse-grained variation in house prices and looks like Orange County, CA. If is close to
, then the county is dominated by coarse-grained variation in house prices and looks like Orange County, CA. If is close to  , then the county is dominated by fine-grained variation in house prices and looks more like Los Angeles, CA. In the analysis below, I’m going to show how to estimate in simulated data.
, then the county is dominated by fine-grained variation in house prices and looks more like Los Angeles, CA. In the analysis below, I’m going to show how to estimate in simulated data.
3. Naïve Estimate of λ
One way to estimate would be to look at a variance ratio. You might first compute the average price in each neighborhood,
(3) 
and then look at the ratio of the variance of the neighborhood-level average prices to the total house-price variance:
(4) 
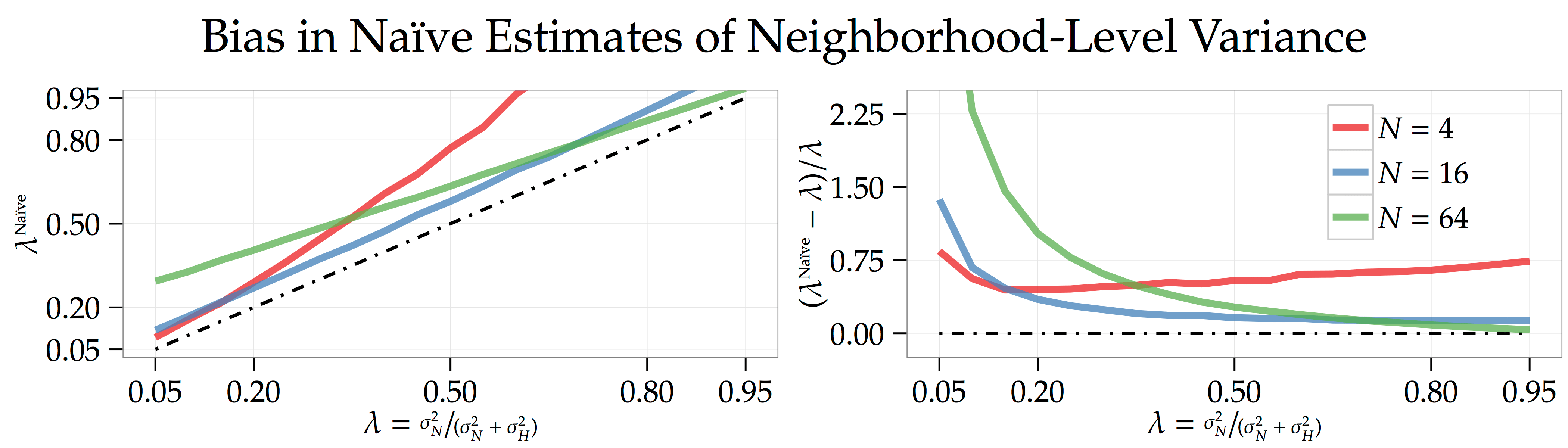
The thought process behind this calculation is really simple. If different neighborhoods have very different prices, then there should be a lot of variation in the average neighborhood-level price. In fact, it turns out to be too simple. While it is true that this naïve calculation will generate a higher in counties with lots of coarse-grained neighborhood-level variation, it will also be high in counties with lots of fine-grained house-to-house variation.
To see why, let’s look at the variance of the average price in each county:
(5) 
This variance consists of  parts: the true neighborhood-level variance,
parts: the true neighborhood-level variance,  ; differences in neighborhood-level prices from fine-grained variation,
; differences in neighborhood-level prices from fine-grained variation,  ; and, a correction for the unknown sample mean,
; and, a correction for the unknown sample mean,  . If we solve for the true amount of neighborhood-level variation,
. If we solve for the true amount of neighborhood-level variation,
(6) 
we see that it’s going to be smaller than the variation in neighborhood-level average prices. Counties with lots of fine-grained, house-to-house differences look like they have too much neighborhood-level house-price variation. What’s more, in the simulations plotted below [code] where the county has  houses, you can see that the nature of this bias is going to vary in a non-trivial way as the number of neighborhoods and the amount of coarse-grained, neighborhood-level variation changes.
houses, you can see that the nature of this bias is going to vary in a non-trivial way as the number of neighborhoods and the amount of coarse-grained, neighborhood-level variation changes.
4. Corrected Estimate of λ
In order to fix the problem, we need a way of simultaneously estimating neighborhood-level and house-level price variation and then using the second estimate to correct the bias in the first. It turns out that you can do this by running a simple cross-sectional regression,
(7) 
where  and
and  denote a collection of cleverly-chosen right-hand-side variables that I define below. The key insight is that, if you define these variables correctly, then you can read off both the neighborhood-level and house-level variation from the coefficients.
denote a collection of cleverly-chosen right-hand-side variables that I define below. The key insight is that, if you define these variables correctly, then you can read off both the neighborhood-level and house-level variation from the coefficients.
Here’s how. First, to create the variables that define the neighborhood-level variation, , randomly pair-off each neighborhood within the county so that there are  neighborhood pairs. Then create the variables:
neighborhood pairs. Then create the variables:
(8) ![\begin{align*} \mathbf{x}_1 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left(\frac{H - 1}{2 \cdot (\sfrac{H}{N})}\right)}} \times \left[ \begin{array}{ccc:ccc:ccc:ccc:c} 1 & \cdots & \phantom{-}1 & -1 & \cdots & -1 & 0 & \cdots & \phantom{-}0 & \phantom{-}0 & \cdots & \phantom{-}0 & \cdots \end{array} \right]^{\top} \\ \mathbf{x}_2 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left(\frac{H - 1}{2 \cdot (\sfrac{H}{N})}\right)}} \times \left[ \begin{array}{ccc:ccc:ccc:ccc:c} 0 & \cdots & \phantom{-}0 & \phantom{-}0 & \cdots & \phantom{-}0 & 1 & \cdots & \phantom{-}1 & -1 & \cdots & -1 & \cdots \end{array} \right]^{\top} \\ &\vdots \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-eb2c107de877921ae264726a20d7fcb6_l3.svg "Rendered by QuickLaTeX.com")
So, the first of these variables,  , compares the average price in the first neighborhood to the average price in the second neighborhood, meaning that the variable is mean zero. The scaling by
, compares the average price in the first neighborhood to the average price in the second neighborhood, meaning that the variable is mean zero. The scaling by  then ensures that
then ensures that  for all
for all  .
.
Next, to create the variables that define the house-level variation, , randomly pair-off each house within a neighborhood so that there are  house pairs within each neighborhood and
house pairs within each neighborhood and  pairs in total. Then, use these house pairs to create the variables:
pairs in total. Then, use these house pairs to create the variables:
(9) ![\begin{align*} \mathbf{y}_1 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left( \frac{H-1}{2 \cdot 1} \right)}} \times \left[ \begin{array}{ccccccc:c} 1 & -1 & 0 & \phantom{-}0 & \cdots & 0 & \phantom{-}0 & \cdots \end{array} \right]^{\top} \\ \mathbf{y}_2 &= {\textstyle \sqrt{\frac{1}{2} \cdot \left(\frac{H-1}{2 \cdot 1}\right)}} \times \left[ \begin{array}{ccccccc:c} 0 & \phantom{-}0 & 1 & -1 & \cdots & 0 & \phantom{-}0 & \cdots \end{array} \right]^{\top} \\ &\vdots \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-209bb33660d8123092ee45afe20c9023_l3.svg "Rendered by QuickLaTeX.com")
So, the first of these variables,  , compares the price of the first house to the price of the second house, meaning that the variable is mean zero. The scaling by
, compares the price of the first house to the price of the second house, meaning that the variable is mean zero. The scaling by  ensures that
ensures that  for all
for all 
Because these right-hand-side variables are orthogonal to one another,
(10) 
we can then use their coefficients to estimate
(11) 
and thus generated an unbiased estimate of :
(12) 
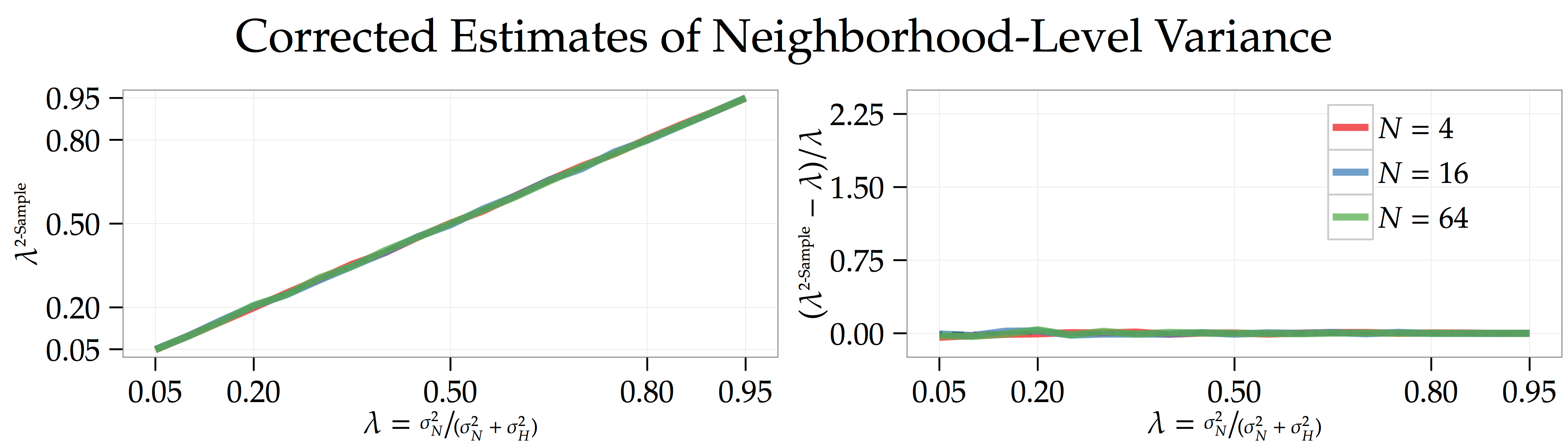
The simulations below [code] use the exact sample parameter values as above but calculate using this correction. All of the earlier bias disappears.
You must be logged in to post a comment.