1. Introduction
In my paper Feature Selection Risk (2014), I study a problem where assets have  different attributes and traders try to identify which
different attributes and traders try to identify which  of these attributes matter via price changes:
of these attributes matter via price changes:
(1) ![\begin{align*} \Delta p_n &= p_n - \mathrm{E}[p_n] = \sum_{q=1}^Q \beta_q \cdot x_{n,q} + \epsilon_n \qquad \text{where} \qquad K = \Vert {\boldsymbol \beta} \Vert_{\ell_0} = \sum_{q=1}^Q 1_{\{ \beta_q \neq 0 \}} \notag \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-61b486123cee5de4e870b72d62eeaa04_l3.svg "Rendered by QuickLaTeX.com")
with each asset’s exposure to a given attribute given by  and the noise is given by
and the noise is given by  . In the limit as
. In the limit as  ,
,  ,
,  , and
, and  there exists both a signal opacity bound,
there exists both a signal opacity bound,  , as well as a signal recovery bound,
, as well as a signal recovery bound,  :
:
(2) 
with  in units of transactions. I explain what I mean by “
in units of transactions. I explain what I mean by “ ” in Section 4 below. These
” in Section 4 below. These  thresholds separate the regions where traders are arbitrarily bad at identifying the shocked attributes (i.e.,
thresholds separate the regions where traders are arbitrarily bad at identifying the shocked attributes (i.e.,  ) from the regions where traders can almost surely identify the shocked attributes (i.e.,
) from the regions where traders can almost surely identify the shocked attributes (i.e.,  ). i.e., if traders have seen fewer than transactions, then they have no idea which shocks took place; whereas, if traders have seen more than transactions, then they can pinpoint exactly which shocks took place.
). i.e., if traders have seen fewer than transactions, then they have no idea which shocks took place; whereas, if traders have seen more than transactions, then they can pinpoint exactly which shocks took place.
In this post, I show that the signal opacity and recovery bounds become arbitrarily close in a large market. The analysis in this post primarily builds on work done in Donoho and Tanner (2009) and Wainwright (2009).
2. Motivating Example
This sort of inference problem pops up all the time in financial settings. Suppose you moved away from Chicago a year ago, and now you’re moving back and looking for a house. When studying a list of recent sales prices, you find yourself a bit surprised. People seem to have changed their preferences for  of
of  different amenities:
different amenities:  a car garage,
a car garage,  a third bedroom,
a third bedroom,  a half-circle driveway,
a half-circle driveway,  granite countertops,
granite countertops,  energy efficient appliances,
energy efficient appliances,  central A/C, or
central A/C, or  a walk-in closet? The mystery amenity is raising the sale price of some houses by
a walk-in closet? The mystery amenity is raising the sale price of some houses by  dollars. How many sales do you need to see in order to figure out which of the amenities realized the shock?
dollars. How many sales do you need to see in order to figure out which of the amenities realized the shock?
The answer is  . How did I arrive at this number? Suppose you found one house with amenities
. How did I arrive at this number? Suppose you found one house with amenities  , a second house with amenities
, a second house with amenities  , and a third house with amenities
, and a third house with amenities  . The combination of the price changes for these houses reveals exactly which amenity has been shocked. i.e., if only the first house’s price was too high,
. The combination of the price changes for these houses reveals exactly which amenity has been shocked. i.e., if only the first house’s price was too high, ![\Delta p_1 = p_1 - \mathrm{E}[p_1] = \beta](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-192f208edef697e5db9b60ed0bf7e90d_l3.svg "Rendered by QuickLaTeX.com") , then Chicagoans must have changed their preferences for car garages:
, then Chicagoans must have changed their preferences for car garages:
(3) 
By contrast, if  , then people must value walk-in closets more than they did a year ago.
, then people must value walk-in closets more than they did a year ago.
Here’s the key point. The problem changes character at  observations. sales is just enough information to answer yes or no questions and rule out the possibility of no change:
observations. sales is just enough information to answer yes or no questions and rule out the possibility of no change:  .
.  sales simply narrows your error bars around the exact value of
sales simply narrows your error bars around the exact value of  .
.  sales only allows you to distinguish between subsets of amenities. e.g., seeing just the first and second houses with unexpectedly high prices only tells you that people like either half-circle driveways or walk-in closets more… not which one.
sales only allows you to distinguish between subsets of amenities. e.g., seeing just the first and second houses with unexpectedly high prices only tells you that people like either half-circle driveways or walk-in closets more… not which one.
Yet, the dimensionality in this toy example can be confusing. There is obviously something different about the problem at observations, but there is still some information contained in the first observations. e.g., even though you can’t tell exactly which attribute realized a shock, you can narrow down the list of possibilities to attributes out of . If you just flipped a coin and guessed after seeing transactions, you would have an error rate of  . This is no longer true in higher dimensions. i.e., even in the absence of any noise, seeing any fraction
. This is no longer true in higher dimensions. i.e., even in the absence of any noise, seeing any fraction  of the required observations for
of the required observations for  will leave you with an error rate that is within a tiny neighborhood of
will leave you with an error rate that is within a tiny neighborhood of  as the number of attributes gets large.
as the number of attributes gets large.
3. Non-Random Analysis
I start by exploring how the required number of observations, , moves around as I increase the number of attributes in the setting where there is only  shock and the data matrix is non-random. Specifically, I look at the case where and
shock and the data matrix is non-random. Specifically, I look at the case where and  . My goal is to build some intuition about what I should expect in the more complicated setting where the data
. My goal is to build some intuition about what I should expect in the more complicated setting where the data  is a random matrix. Here, in this simple setting, the ideal data matrix would be
is a random matrix. Here, in this simple setting, the ideal data matrix would be  -dimensional and look like:
-dimensional and look like:
(4) ![\begin{equation*} \underset{4 \times 15}{\mathbf{X}} = \left[ \begin{matrix} 1 & 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 \end{matrix} \ \ \ \begin{matrix} 0 & 1 & 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 1 & 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{matrix} \right] \end{equation*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-c9654d5e3c73000da35573acd23905a3_l3.svg "Rendered by QuickLaTeX.com")
where each column of the data matrix corresponds to a number  in binary.
in binary.
Let  be a function that eats
be a function that eats  observed price changes and spits out the set of possible preference changes that might explain the observed price changes. e.g., if traders only see the st transaction, then they can only place the shock in of sets containing
observed price changes and spits out the set of possible preference changes that might explain the observed price changes. e.g., if traders only see the st transaction, then they can only place the shock in of sets containing  attributes each:
attributes each:
(5) 
The nd transaction then allows traders to split each of these larger sets into smaller ones and place the shock in a set of  possibilities:
possibilities:
(6) 
With the rd transaction, traders can tell that the actual shock is either of possibilities:
(7) 
The  th observation then closes the case against the offending attribute.
th observation then closes the case against the offending attribute.
Here’s the key observation. Only the absolute difference between  matters when computing the size of the output of . If traders have seen
matters when computing the size of the output of . If traders have seen  transaction, then they can tell which subset of
transaction, then they can tell which subset of  attributes has realized a shock. If traders have seen
attributes has realized a shock. If traders have seen  transactions, then they can tell which subset of
transactions, then they can tell which subset of  attributes has realized a shock. If traders have seen
attributes has realized a shock. If traders have seen  observations, then they can tell which subset of
observations, then they can tell which subset of  attributes has realized a shock. Thus, after seeing any number of observations
attributes has realized a shock. Thus, after seeing any number of observations  , traders can place the shock in a set of size
, traders can place the shock in a set of size  . i.e., a trader has the same amount of information about which attribute has realized a shock in (i) a situation where
. i.e., a trader has the same amount of information about which attribute has realized a shock in (i) a situation where  and he’s seen
and he’s seen  transactions as in (ii) a situation where and he’s seen transactions.
transactions as in (ii) a situation where and he’s seen transactions.
The probability that traders select the correct attribute after seeing only observations is given by  assuming uniform priors. Natural numbers are hard to work with analytically, so let’s suppose that traders observe some fraction of the required number of observations . i.e., for some traders see
assuming uniform priors. Natural numbers are hard to work with analytically, so let’s suppose that traders observe some fraction of the required number of observations . i.e., for some traders see  observations. We can then perform a change of variables
observations. We can then perform a change of variables  and answer the question: “How much does getting additional observation improve traders’ error rate?”
and answer the question: “How much does getting additional observation improve traders’ error rate?”
(8) ![\begin{align*} \frac{1}{N_R} \cdot \frac{d}{d\alpha}\left[ \, 2^{- (N_R - N)} \, \right] = - \log(2) \cdot e^{- \alpha \cdot \log(2) \cdot N_R} \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-aed714b93d9cbbf093a71edae530f1c7_l3.svg "Rendered by QuickLaTeX.com")
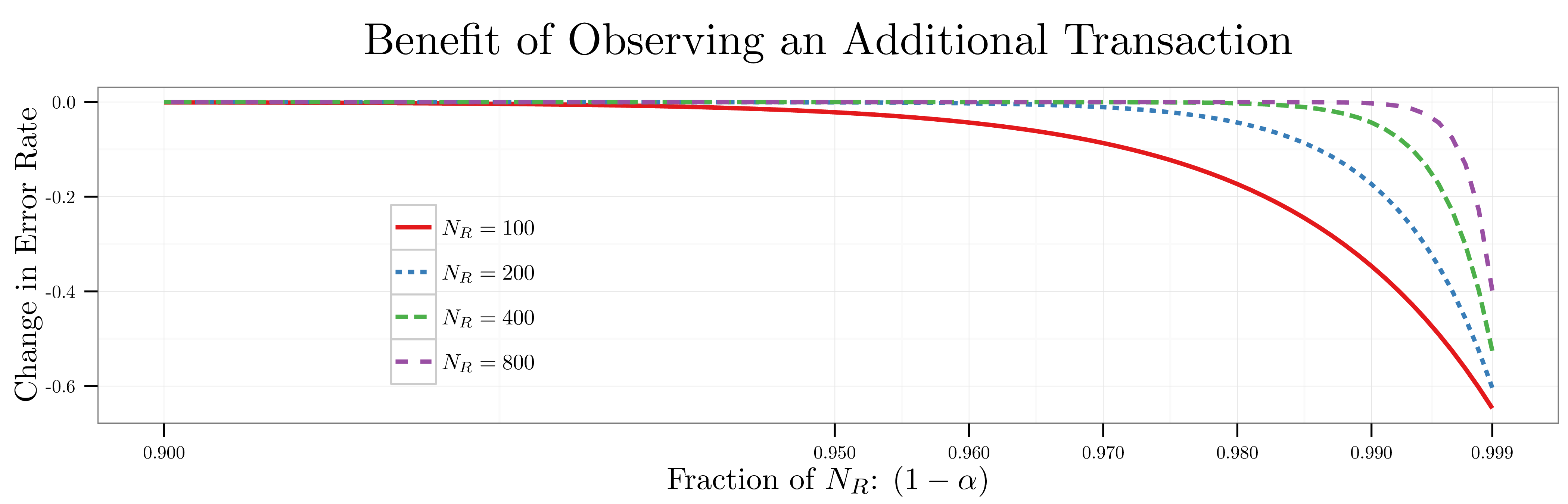
I plot this statistic for ranging from  to
to  below. When , a trader’s predictive power doesn’t start to improve until he sees
below. When , a trader’s predictive power doesn’t start to improve until he sees  transactions (i.e.,
transactions (i.e.,  of ); by contrast, when
of ); by contrast, when  a trader’s predictive power doesn’t start to improve until he’s seen
a trader’s predictive power doesn’t start to improve until he’s seen  transactions (i.e.,
transactions (i.e.,  of ). Here’s the punchline. As I scale up the original toy example from attributes to million attributes, traders effectively get
of ). Here’s the punchline. As I scale up the original toy example from attributes to million attributes, traders effectively get  useful information about which attributes realized a shock until they come within a hair’s breadth of the signal recovery bound . The opacity and recovery bounds are right on top of one another.
useful information about which attributes realized a shock until they come within a hair’s breadth of the signal recovery bound . The opacity and recovery bounds are right on top of one another.
4. Introducing Randomness
Previously, the matrix of attributes was strategically chosen so that the set of observations that traders see would be as informative as possible. Now, I want to relax this assumption and allow the data matrix to be random with elements  :
:
(9) 
where  denotes idiosyncratic shocks affecting asset
denotes idiosyncratic shocks affecting asset  in units of dollars. For a given triplet of integers
in units of dollars. For a given triplet of integers  with
with  , I want to know whether solving the linear program:
, I want to know whether solving the linear program:
(10) 
recovers the true  when it is
when it is  -sparse. i.e., when has only non-zero entries
-sparse. i.e., when has only non-zero entries  . Since
. Since  the linear system is underdetermined; however, if the level of sparsity is sufficiently high (i.e., is sufficiently small), then there will be a unique solution with high probability.
the linear system is underdetermined; however, if the level of sparsity is sufficiently high (i.e., is sufficiently small), then there will be a unique solution with high probability.
First, I study the case where there is no noise (i.e., where  ), and I ask: “What is the minimum number of observations needed to identify the true with probability
), and I ask: “What is the minimum number of observations needed to identify the true with probability  for
for  using the linear program in Equation (10)?” I remove the noise to make the inference problem as easy as possible for traders. Thus, the proposition below which characterizes this minimum number of observations gives a lower bound. I refer to this number of observations as the signal opacity bound and write it as . The proposition shows that, whenever traders have seen observations, I can make traders’ error rate arbitrarily bad (i.e.,
using the linear program in Equation (10)?” I remove the noise to make the inference problem as easy as possible for traders. Thus, the proposition below which characterizes this minimum number of observations gives a lower bound. I refer to this number of observations as the signal opacity bound and write it as . The proposition shows that, whenever traders have seen observations, I can make traders’ error rate arbitrarily bad (i.e.,  ) by increasing the number of attributes (i.e.,
) by increasing the number of attributes (i.e.,  ).
).
Proposition (Donoho and Tanner, 2009): Suppose  ,
,  , and
, and  with
with  . The linear program in Equation (10) will recover a fraction if the time whenever:
. The linear program in Equation (10) will recover a fraction if the time whenever:
(11) 
where  .
.
Next, I turn to the case where there is noise (i.e., where  ), and I ask: “How many observations do traders need to see in order to identify the true with probability in an asymptotically large market using the linear program in Equation (10)?” Define traders’ error rate after seeing observations as:
), and I ask: “How many observations do traders need to see in order to identify the true with probability in an asymptotically large market using the linear program in Equation (10)?” Define traders’ error rate after seeing observations as:
(12) ![\begin{align*} \mathrm{Err}[N] &= \frac{1}{{Q \choose K}} \cdot \sum_{\substack{\mathcal{K} \in \mathcal{Q} \\ |\mathcal{K}| = K}} \mathrm{Pr}(\widehat{\boldsymbol \beta} \neq {\boldsymbol \beta}) \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-34cf0d5b92083a52a184ce78eec484c8_l3.svg "Rendered by QuickLaTeX.com")
 denotes the probability that the linear program in Equation (10) chooses the wrong subset of attributes (i.e., makes an error) given the true support
denotes the probability that the linear program in Equation (10) chooses the wrong subset of attributes (i.e., makes an error) given the true support  and averaging over not only the measurement noise,
and averaging over not only the measurement noise,  , but also the choice of the Gaussian attribute exposure matrix, . Traders’ error rate is the weighted average of these probabilities over every shock set of size . Traders identify the true
, but also the choice of the Gaussian attribute exposure matrix, . Traders’ error rate is the weighted average of these probabilities over every shock set of size . Traders identify the true  with probability in an asymptotically large market if:
with probability in an asymptotically large market if:
(13) ![\begin{align*} \lim_{\substack{K,N,Q \to \infty \\ \sfrac{K}{Q} \to 0}} \mathrm{Err}[N] &= 0 \end{align*}](https://alexchinco.com/wp-content/ql-cache/quicklatex.com-58c9bb88049ae8e5206718106055daf5_l3.svg "Rendered by QuickLaTeX.com")
Thus, the proposition below which characterizes this number of observations gives an upper bound of sorts. I refer to this number of observations as the signal recovery bound and write it as . i.e., the proposition shows that, whenever traders have seen observations, they will be able to recovery almost surely no matter how large I make the market.
Proposition (Wainwright, 2009): Suppose , , , and , then traders can identify the true with probability in an asymptotically large market if for some constant  :
:
(14) 
The only cognitive constraint that traders face is that their selection rule must be computationally tractable. Under minimal assumptions a convex optimization program is computationally tractable in the sense that the computational effort required to solve the problem to a given accuracy grows moderately with the dimensions of the problem. Natarajan (1995) explicitly shows that  constrained linear programming is NP-hard. This cognitive constraint is really weak in the sense that any selection rule that you might look up in an econometrics or statistics textbook (e.g., forward stepwise regression or LASSO) is going to be computationally tractable. After all, they have to be executed on computers.
constrained linear programming is NP-hard. This cognitive constraint is really weak in the sense that any selection rule that you might look up in an econometrics or statistics textbook (e.g., forward stepwise regression or LASSO) is going to be computationally tractable. After all, they have to be executed on computers.
5. Discussion

What is really interesting is that the signal opacity bound, , and the signal recovery bound, , basically sit right on top of one another when the market gets large just as you would expect from the analysis in Section 3. The figure above plots each bound on a log-log scale for varying levels of sparsity. It’s clear from the figure that the bounds are quite close. The figure below plots the relative gap between these bounds:
(15) 
i.e., it plots how big the gap is relative to the size of the signal recover bound . For each level of sparsity, the gap is shrinking as I add more and more attributes. This is an identical result as in the figure from Section 3: as the size of the market increases, traders learn next to nothing from each successive observation until they get within an inch of the signal recovery bound. The only difference here is that now there are an arbitrary number of shocks and the data matrix is random.

You must be logged in to post a comment.